Model-Based vs. Model-Free RL
To illustrate this distinction, imagine planning a trip. If you know which roads will be congested, you can take an alternative route, reducing travel time and fuel consumption. Similarly, if you are aware of the topics covered in an upcoming exam, you can focus your study on the most relevant material, avoiding unnecessary effort. In both cases, having a predictive model allows for better decision-making, optimizing resources and efficiency. This principle is the foundation of Model-Based RL (MBRL). In MBRL, the agent builds or learns a model of the environment that helps it predict the consequences of its actions. This predictive ability enables strategic planning, leading to more efficient learning. However, developing an accurate model requires extensive data and computational resources, making it a more complex approach. On the other hand, Model-Free RL (MFRL) does not rely on a predictive model. Instead, the agent learns purely through trial and error, refining its actions based on rewards without trying to anticipate future states. While simpler to implement, this approach often requires more experience to achieve optimal performance.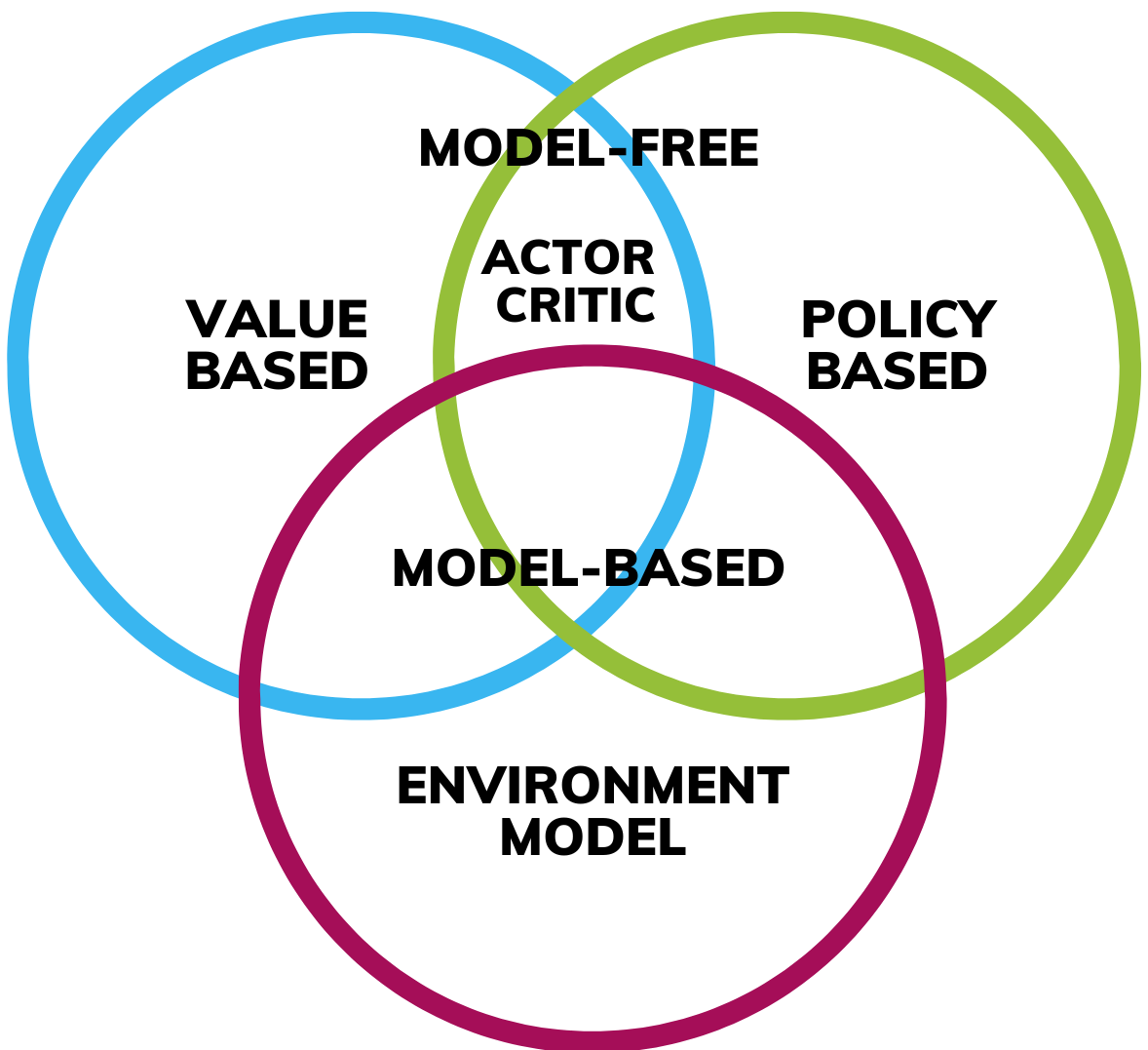
Value-Based RL
The agent learns a function that assigns values to states or state-action pairs, estimating how good a particular state or action is in terms of long-term rewards. Once the agent finds the optimal value function, it selects actions that maximize these values.Policy-Based RL
Instead of learning value functions, the agent directly learns a policy—a probability distribution over actions given states. This approach is particularly useful for environments with continuous or high-dimensional action spaces. Policy gradients are commonly used to refine the policy toward maximizing rewards.Actor-Critic RL
This method combines both value-based and policy-based approaches. The actor learns and updates the policy, selecting actions, while the critic evaluates these actions using a value function. The critic helps guide the actor toward better decisions by providing feedback, balancing efficiency and stability in learning.In summary, RL encompasses a diverse range of methods, each suited to different problem settings and requirements. This taxonomy offers a high-level overview of the key distinctions between these approaches, helping you select the most appropriate one for your task.