Artificial Intelligence
AI can be described as the combination of science and engineering that aims to equip machines with the ability to mimic certain biological behaviors observed in humans and animals, such as reasoning, visual perception, speech recognition, decision-making, and learning.While learning is a key part of intelligence, it does not represent its entirety. Learning is more specifically linked to the ability to solve particular problems or complete specific tasks. This distinction has led to the development of a subfield of AI known as machine learning (ML).
Machine Learning
Unlike general AI, which aims to replicate human or animal intelligence to handle complex and diverse tasks, ML focuses on acquiring knowledge from data related to specific tasks, producing accurate results. ML differs from the broader concept of AI in that it does not attempt to mimic human intelligence. Instead, it seeks to learn and solve specific problems without requiring explicit programming or instructions.ML is broadly categorized into three subdivisions, each designed to address different types of problems depending on the nature of the data used.
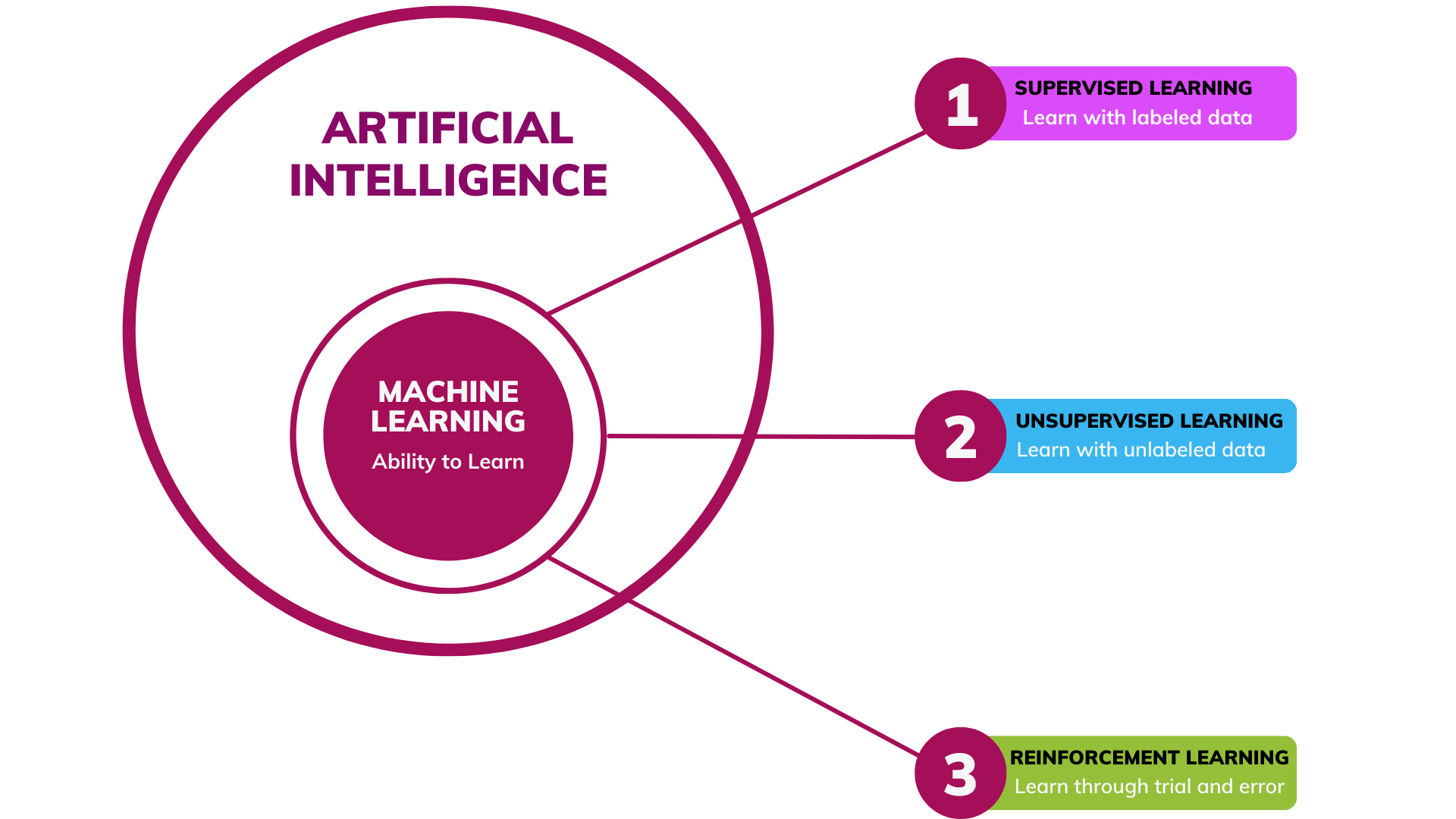
- Supervised Machine Learning: This approach relies on labeled datasets (typically labeled by humans) to learn specific tasks. It is widely used in applications such as image classification, recommendation systems, and predictive analytics, making it one of the most popular subcategories in the field of machine learning.
- Unsupervised Machine Learning: Unlike supervised learning, this approach does not require labeled data. Instead, it focuses on discovering patterns, structures, or similarities within a dataset. Though less commonly used than supervised learning, unsupervised learning is valuable in tasks like clustering and anomaly detection.
- Reinforcement Learning: Unlike the previous two subcategories, RL does not rely on pre-collected datasets, whether labeled or unlabeled. Instead, it trains machines through trial-and-error processes to identify the optimal sequence of actions that maximize cumulative rewards.
Reinforcement Learning
Reinforcement learning focuses on determining the best course of action.In simple terms, RL is the process of improving performance through trial and error, where there is not an explicit teacher. The core idea behind RL is that when an action leads to a rewarding outcome, the system is more likely to repeat that action in the future. Unlike supervised and unsupervised learning, RL doesn’t require a large, pre-collected dataset or labeled data to learn a new task. Instead, it learns through interactions with its environment, gradually discovering what works based on the feedback it receives. Through this process of learning from feedback, RL offers a unique approach to solving problems where traditional learning methods fall short. In the next section, we’ll explore more concrete concepts about RL.